
ViT模型详解
一、网络结构
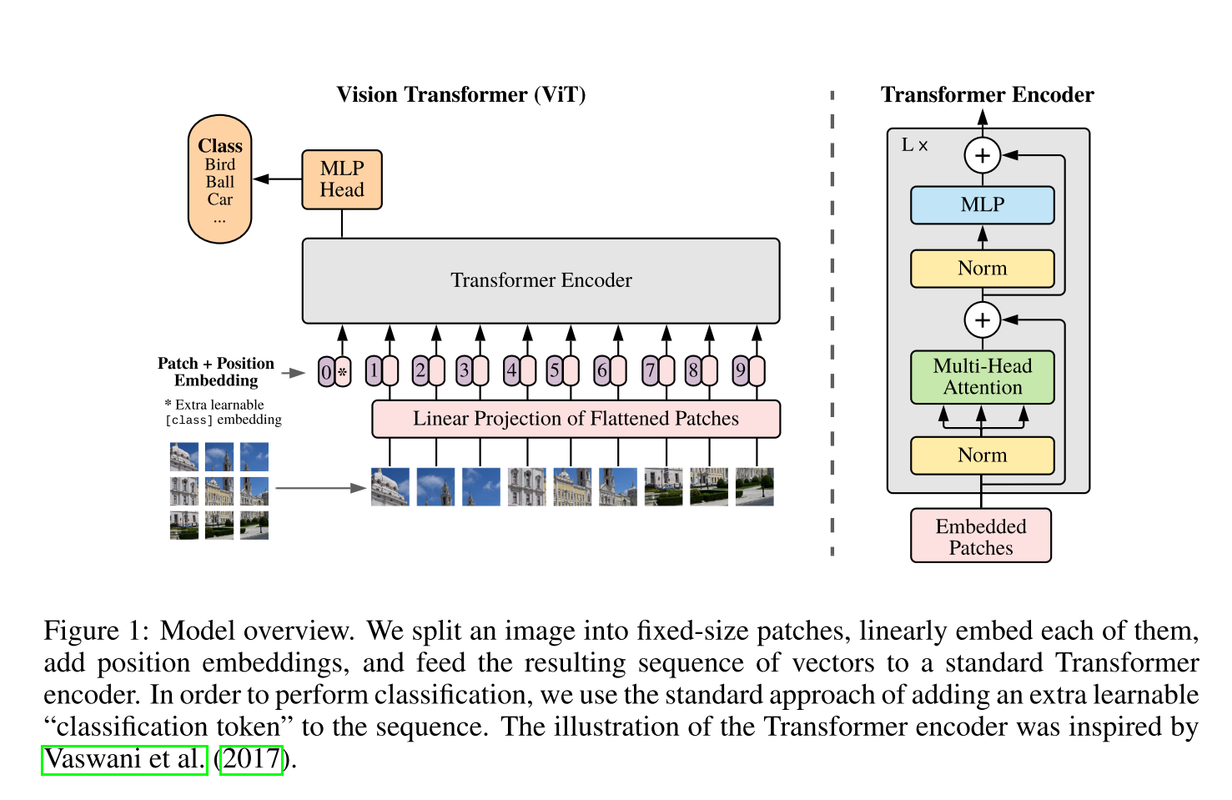
二、详情
1、补丁嵌入
-
原始图像:H×W×C,高度,宽度,通道数
-
补丁(patch):N×(P^2×C),
N=H×W/(P×P)叫补丁数或者输入序列长度
(P,P)叫补丁的分辨率
将图像分割成多个补丁(patch),将补丁平铺成一维数据格式,再通过线性投影将补丁平坦化映射到低维空间
2、位置嵌入
- 添加位置编码表示两个补丁之间的距离,即添加了补丁的位置信息
网络自动学习
sin-cos规则
- 将向量的维度切分为奇数行和偶数行
- 偶数行采用sin函数编码,奇数行采用cos函数编码
- 然后按照原始行号拼接
2
3
4
5
6
7
8
9
10
# hid_j是0-511,d_hid是512,position表示单词位置0~N-1
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
# 每个单词位置0~N-1都可以编码得到512长度的向量
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
# 偶数列进行sin
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
# 奇数列进行cos
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
3、类别标记
- 输出特征加上一个线性分类器实现分类
cls_token方式,cls位置表示向量
2
3
4
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b=b) # 复制令牌,并生成新的转变为(B,N,D)格式的张量
x = torch.cat((cls_tokens, x), dim=1) # 类别标记拼接补丁嵌入
4、Transformer编码器
1 | class Attention(nn.Module): |
5、MLP多层感知机/前馈神经网络
1 | class FeedForward(nn.Module): # 前馈神经网络FFN,也叫多层感知机MLP |
相关推荐

评论