
Transformer
1、Transformer架构
-
采用编码器-解码器架构
-
transformer是纯基于注意力机制
$$
Attention(Q,K,V) = softmax(\frac {QK^T}{\sqrt{d_k}})V
$$- Q(query)查询序列
- K(key)待查序列
- V(value)自身含义编码序列
-
Q和K进行点乘(内积),点乘的结果是一个向量在另一向量投影的长度,它是一个标量,它可以反映两个向量的相似度,两个向量点乘结果越大,它们的相似度越高,距离越近,越关注。
-
为了防止其结果过大,再除以$\sqrt {d_k}$ ,也就是K向量的维度。
-
再使用Softmax回归将结果归一化为概率分布,乘以V就得到了加权求和形式。
2、网络结构
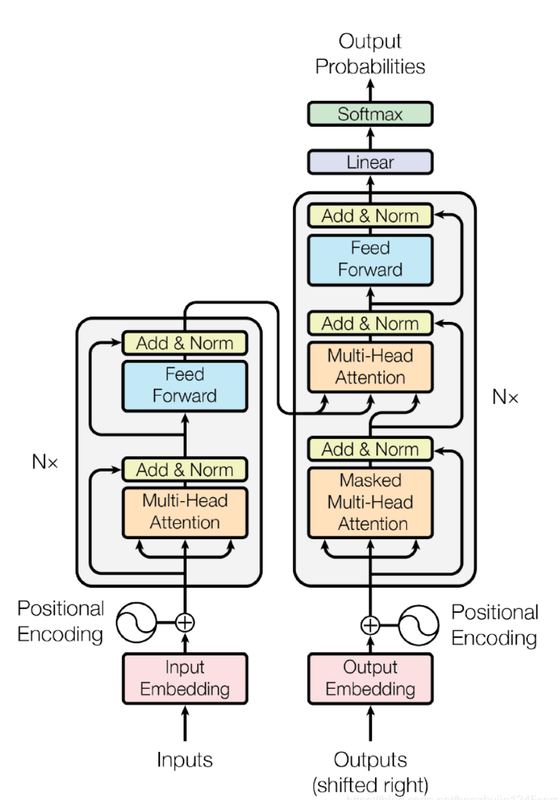
2.1 encoding 部分
- 位置编码
- 多头注意力机制
- 前馈神经网络
其中,Add表示残差连接,Norm表示layer normalize(层归一化)
2.2 decoding部分
-
Mask(掩码)
-
线性层和softmax层
线性层相当于一个全连接神经网络
相关推荐

评论